SRA Experience Recap
As a rising high school junior, I was honored to be part of a highly selective summer research program: Summer Research Academies at UC Santa Barbara in the summer of 2021. The program has an overall acceptance rate of 18.9% and I was one of five girls in a group of 26 students enrolled in its 9th track called Machine Intelligence: An Introduction to Optimization and Machine learning.
During the four-week program, my two teammates and I were challenged to create a machine learning project. Prompted by a common interest in music, we decided to use Python to code an LSTM model that can predict a sequence of tonal melodies.
Below I have included a summary of our research and findings:
My Project - Musics Generation using Machine
Overview
Music is an important aspect of our daily life and exists in much of the media we digest, such as background music, cellular ringtones, and alarms. However, how music and the innovative field of artificial intelligence can be combined is an under-researched study as music depends on both concrete and abstract factors, and freedom in both the expression and interpretation of emotion in music increases the complexity for machines to fully understand music independently. However, what computers are very good at, is doing mathematical and procedural calculations. So, we decided to focus on the concrete aspects of music, specifically the pitch and rhythm, and explore the possibility of these being generated through a machine learning algorithm.
Literature Review
Google Magenta project utilizes the Transformer model as the neural network, where a stack of encoders are passed into a black box function and a stack of decoding sequences in the same number is outputted. Its Music Transformer mainly focuses on three tasks: unconditional, continuation, and accompaniment generation. We decided to model our project on the unconditional generator, as it is the only one that does not require user input and has a wider range of applications. More can be read in my previous post: Music Generation Brainstorm 7/25
Significance
Music generation can be used for many recreational and commercial activities. This can include helping composers write songs, helping media industries save time and money with generated background audios, generating playlists, and even extending the works of deceased or retired composers. In addition to extending works, it can also create songs with styles similar to those deceased or retired composers.
For our project, we would like to investigate how deep learning and artificial intelligence can be used to generate simple musical melodies.
Methodology
Our model is made up of 2 LSTM and dropout layers, with one dense layer at the end. The input to the model is a 10-element long sequence of notes, and the output shape is the number of possible note values the model can guess, also known as the vocabulary. The input is a 10 x 1 vector and the output is a 1xvocab length vector.
We selected the MAESTRO music dataset for our work, a fairly common dataset used for music machine learning projects, including Google’s Magenta.
We extracted the MIDI files from the dataset, removed all possible errors, and converted them into ABC files. Next, we vectorized our data for the model and split away certain unwanted characters that we don’t want to feed into the model. The text elements are then converted into a number, creating a vocabulary.
The model requires an input of a normalized sequence with a length of ten, and output of length vocabulary, the process is repeated for the length of the melodic line and each respective y value is one-hot encoded. Our result model can utilize the softmax activation function to predict each new element. In the end, the output array is converted to its corresponding vocabulary term and back into a midi file.
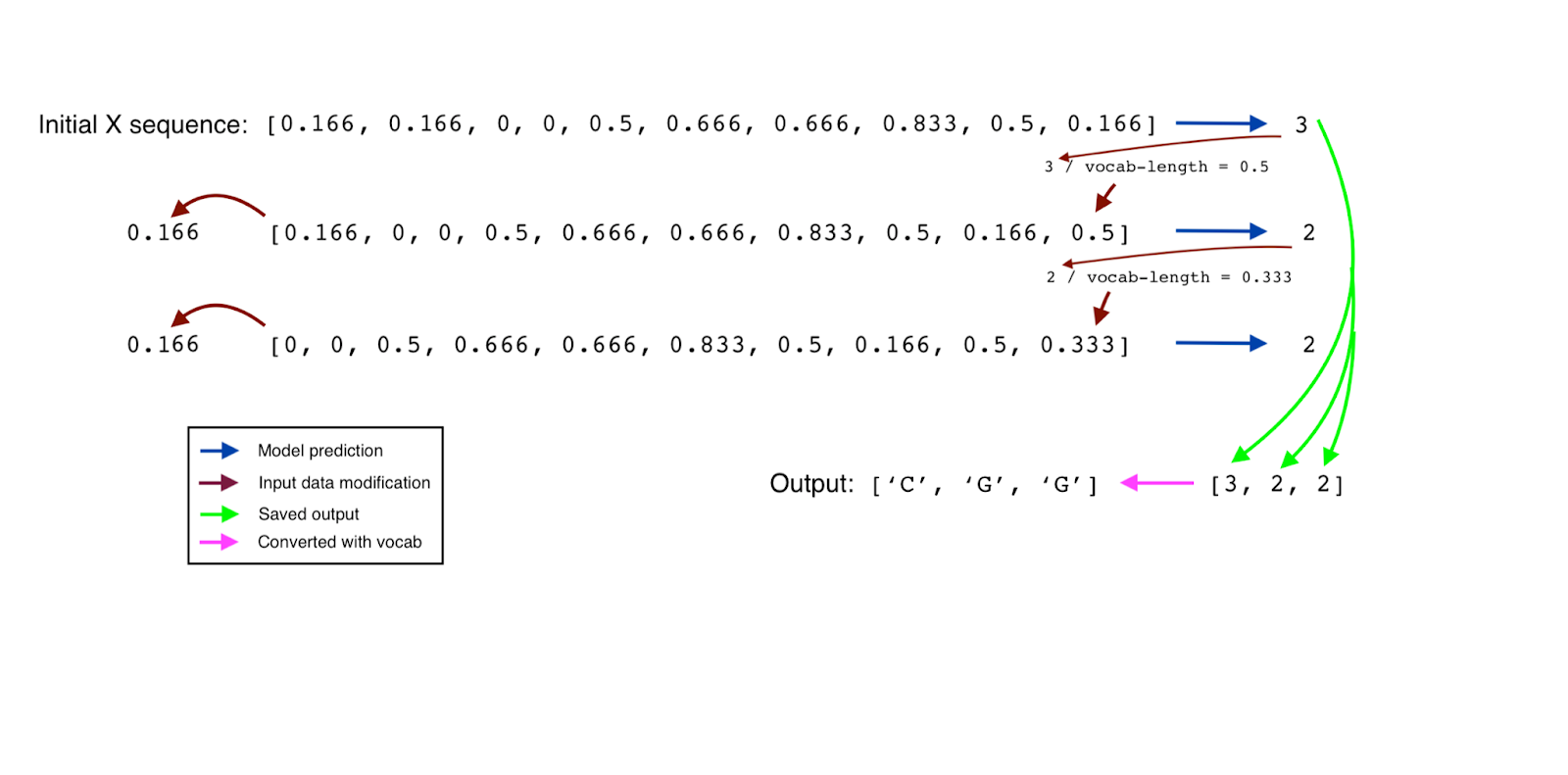
Figure 1: Image of prediction model
Result
We trained our results with a vocabulary length of 324 elements and a data size of about 1000 x and y pairs. We found that the best melody is generated with a loss of 0.1 and accuracy of 70% trained at 250 epochs and a batch size of 128.

Figure 2: Image of sample generated result
Conclusion
Our LSTM model was successful at generating musical melodies. The model was able to produce sequences of tonal notes nicely similar to the process of a text generation model creating a valid sequence of words.
Future Area of improvements
Future research can improve upon this study by training the model on different difficulties, genres, and speeds of music to create more customizable outputs. If we can filter the input and add descriptive tags to the repertoires fed into the training model, then the generated output would match the desired qualities inputted by the user. I believe the next step would be to create such a dataset with labels such as emotion, speed, difficulty, and other qualities we would like to see as customizable functions in a music generation model. ***
In addition, more LSTM layers can be added in order to detect more sophisticated melodic patterns. Additional techniques such as reinforcement learning can be used to improve the model as well.
** Please email me at yirnairenewang@gmail.com if you would like to read our paper or to learn more about our projects
*** The idea of MusicNet will be further explored in the next post.