In the fall of 2021, I joined Aspiring Scholars Directed Research Program (ASDRP) under its Computer Science & Engineering department and more specifically, data science, with my mentor Suresh Subramaniam.
Over the course of three month, my group and I put together a natural language project that can predict the next word given an initial string and presented our findings in the program’s weekly Colloquia meeting to an audience of around 200 people.
Below I have included a summary of our research and findings:
Predict Next Word: Text Generation Using LSTM in a Professional Biomedical Context
Background
Figure 1: A generated text
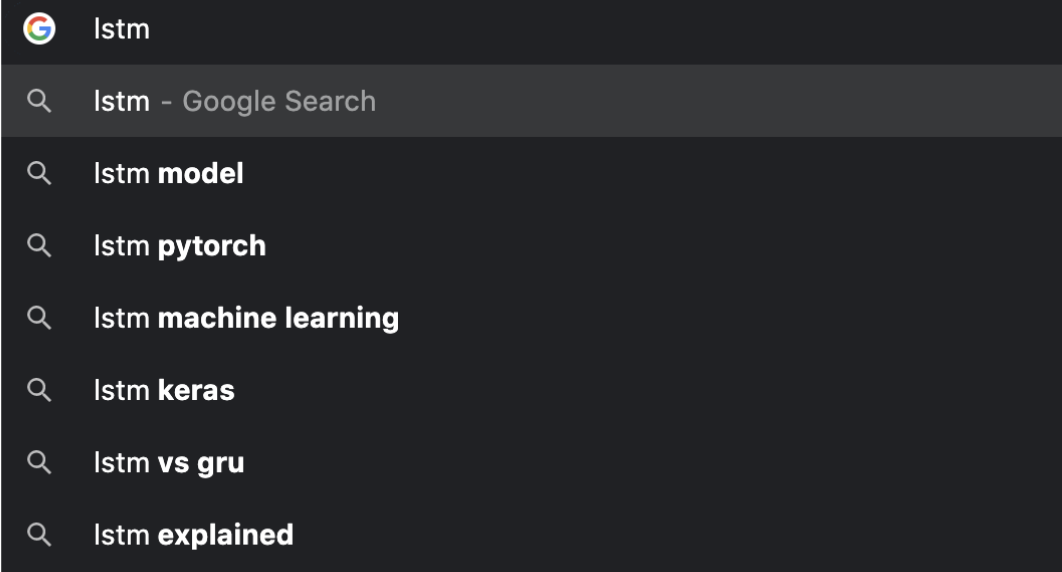
Machine learning is the study of computer algorithms that can be used for discovering patterns and sequences, then make predictions with its findings. Part of machine learning is neural networks which are systems that recognize patterns and solve problems. We used a type of neural network,LSTM, or long short-term memory. LSTM and other language models are commonly used in the world around us. We use it all the time when typing messages to send to friends, emails to teachers, and typing an assignment on Google Docs. Suggestions pop up as you are writing your message. LSTM can remember the order dependence in a sequence and come up with predictions for text generation. The image on this slide is a picture of one example of machine learning. When the user types “LSTM”, it uses previous searches with the same beginning and gives the user suggestions of what they might be looking for. Although sometimes the range of what we are looking for is too specific and the model is not able to return us what we are looking for. Our goal for the project is to create a model that uses bidirectional LSTM to predict text in a biomedical context. With the more terminology it is fed, it will make the results and suggestions even better.
Figure 2: Text prediction on Google search engine
Related studies
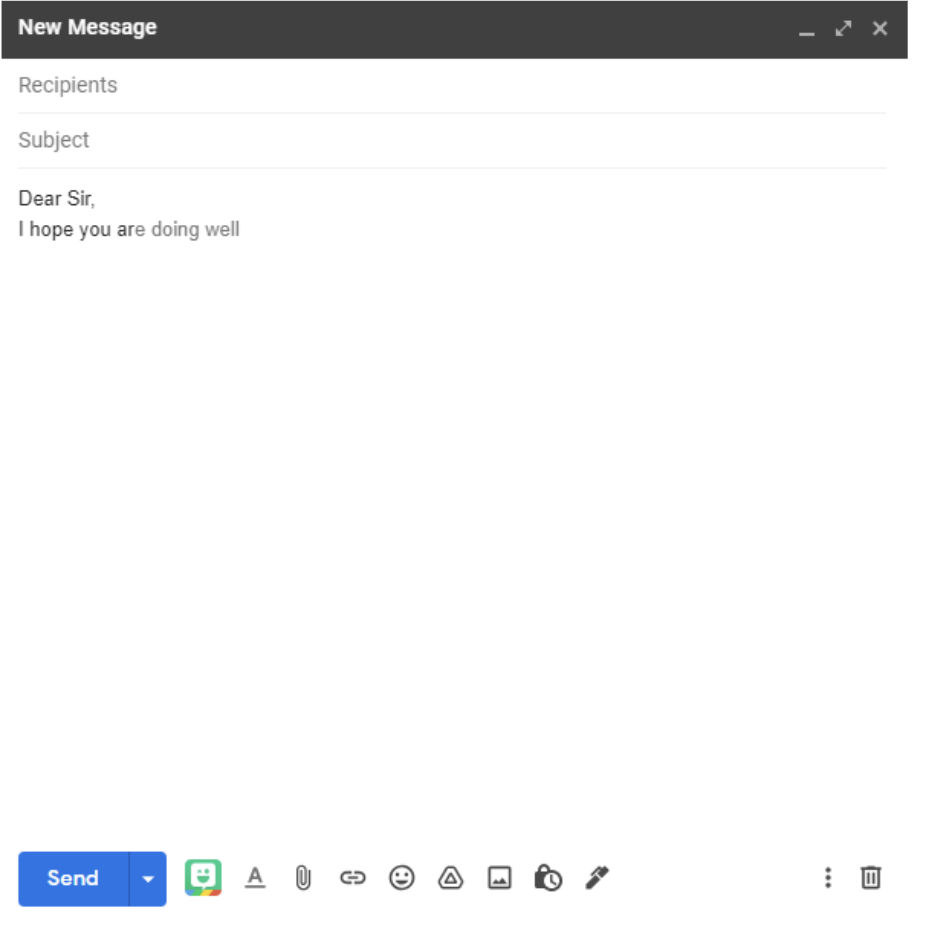
LSTM is commonly used in Gmail, iMessages, Google Docs, and many more. In this photo, Google predicts what you might say using previous user inputs. iMessages does the same, as it suggests words that you have said many times with the phrase that you have typed. Such as if I type “how are” , it may suggest “you” because I have typed and sent that message quite a lot of times.
BERT is another language model that gives the user relevant searches based on what they have looked for before.
One usage of language models is BERT. It is an open source framework that uses surrounding text to figure out what the user may be saying. Google uses BERT for it’s search engine and the suggestions of what you may be searching for.
Another language model that is quite common is GPT2. It contains lots of data from the internet which means it has a lot of potential uses. Although it is mainly used for text autocorrection, such as “Autocorrect” on iMessages and Google Chat / Hangouts.
Figure 3: Text suggestion on Gmail
Significance
The model predicts what might be written next with text generation. It helps us with writing efficient, grammatically correct, and good terminology papers. Text generation can also fix spelling mistakes, and is often used in chatbots or automated journalism instead of manually written. It also lets us use voice overs on websites for our comfortability. If someone has a loss of hearing, they can use the transcripts of a page to help them understand it.
For our project, we would like to investigate how to use deep learning to predict the next word in a phrase that correctly matches the professional context it is written in. In Particular, we tried curating the sources to include biomedical terms.
Methodology
Dataset
We selected the English Wikipedia as the training data source for our work. As of December 7, 2020, this dataset consists of over 4 billion words and 6.4 million articles. This dataset is fairly common for text generation, being used in many projects such as Google’s BERT algorithm that was introduced. We chose Wikipedia because not only does it provide the large and extensive network of grammatically and syntactically correct work written in modern English that would ensure the accuracy of our training result, the wide range of topic areas covered by articles found on the website also satisfy our project goal of narrowing down the scope of text generation to specific professional contexts.
Bi-Directional Long Short Term Memory (Bi-LSMT)
In-text generation, we try to predict the next character or word of the sequence. The text data is generally considered as a sequence of data. For predicting data in the sequence we used deep learning models like RNN or LSTM. We chose LSTM over RNN in this because RNN has problems such as vanishing and exploding gradients due to backpropagation through time. In addition, it is dependent on context only from the past and does not memorize data for a long time, tending to forget their previous inputs, thus making is not very compatible with largest datasets
Since in text generation we have to memorize a large amount of previous data. So for this purpose LSTM is preferred, which takes phrases of text, which are just sequences of words, and uses it to predict the next word. And output a matrix of probability for each word from the dictionary to be next of the given sequence The model will also learn how much similarity is between each word or character and will calculate the probability of each. Using that we will predict or generate the next word or character of sequence. In addition, LSTM performs better in distinguishing between important and unimportant information.
Finally Bidirectional LSTMs is a special case of LSTM that can be used to train two sides, instead of one side of the input sequence. First from left to right on the input sequence and the second in reversed order of the input sequence. It provides one more context to the word to fit in the right context from words coming after and before, this results in faster and fully learning and solving a problem.
Preprocessing
Before the training begins, the text must be edited to remove unnecessary and unneeded symbols. Such as empty strings, line return, Numbers, punctuations, unwanted, and non-English words
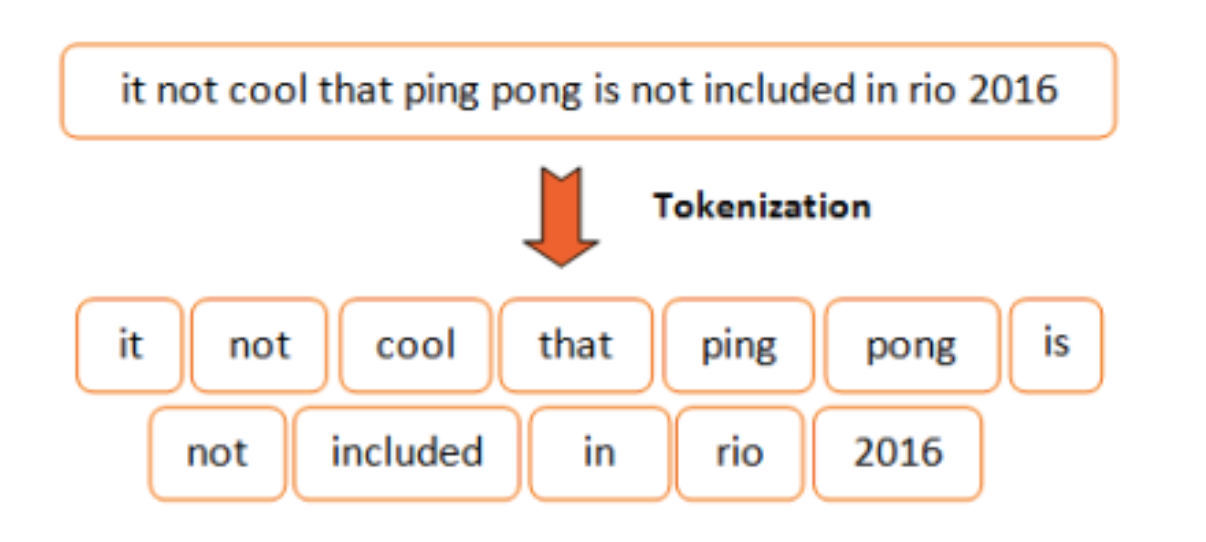
The next step. One of the important normalization methods is called tokenization. It is simply segmenting the continuous running text into individual segments of words. The approach utilized in our projects split inputs over every space and assign an identifier to each word.
Figure 5: Tokenization step example
Even after converting sentences to numerical values, there’s still an issue of providing equal length inputs to our neural networks — not every sentence will be the same length! There are two main ways you can process the input sentences to achieve this — padding the shorter sentences with zeroes, and truncating some of the longer sequences to be shorter.
So now, our line will be represented by a set of padded input sequences that look like the example above. Now that we have our sequences, the next thing we need to do is turn them into x and y, our input values and their labels. When you think about it now that the sentences are represented in this way, all we have to do is take all but the last character as the x and then use the last character as the y on our label.
We do like this above, where for the first sequence, everything up to the 4 is our input and the 2 is our label.
And similarly, here for the second sequence where the input is two words and the is the third word, tokenized to 66.
If we consider this list of tokens as a sentence, then the x is the list up to the last value and the label is the last value which in this case is 70. The y is a one-hot encoded array whether length is the size of the corpus of words and the value that is set to one is the one at the index of the label which in this case is the 70th element.
So now we can build a neural network that can, given a sentence, predict the next word.
Figure 6: Padding and truncating
Figure 7: Predicting a text sequence from a random input sequence
'
This is how the model generates a sequence of text.
First, a random x sequence is selected from the model. It is fed into the model, and the model outputs a one-hot sequence, which is converted to its corresponding number. The encoding output is not shown in this diagram, just the decoded value, for simplicity since this diagram is already pretty dense.
The output of the model is then added to an output array. Before the next prediction, the first element in the x sequence is removed, and the output value is normalized and added to the end. This process is repeated over and over, and at the end, the output array is converted to its corresponding vocabulary term
Result
Training Data
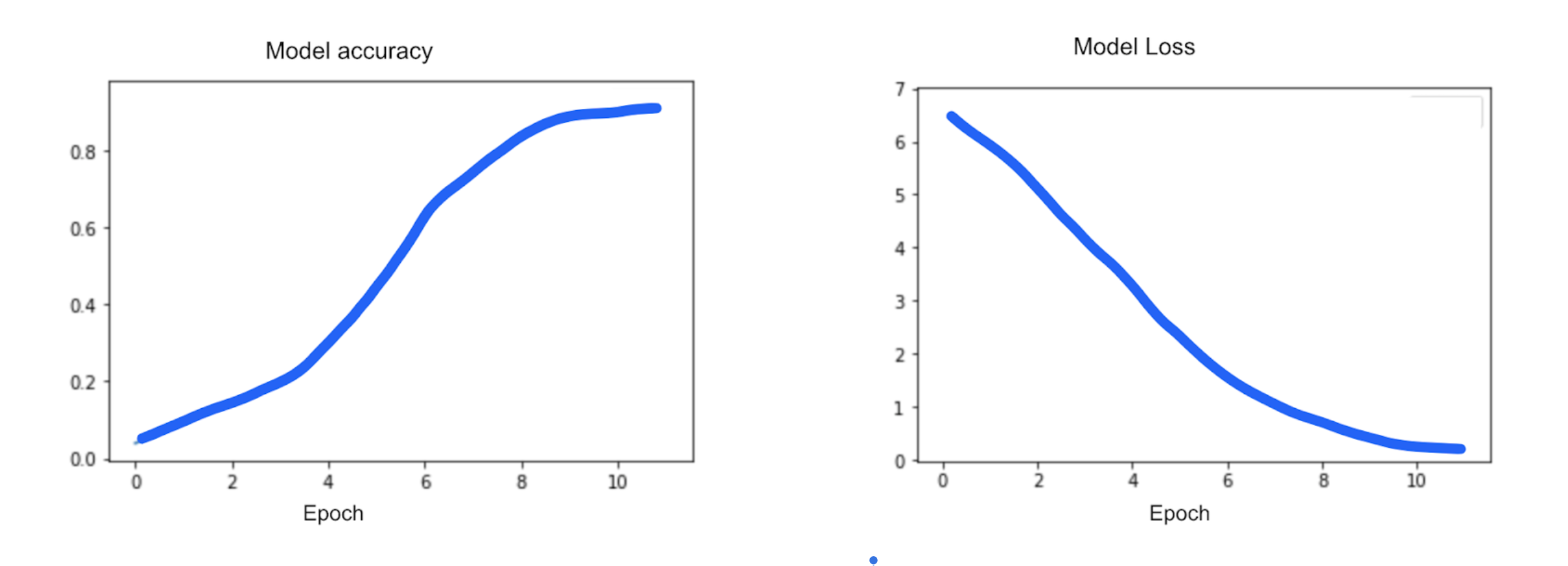
Figure 8. Loss and accuracy during a training of 10 epochs
'
The graphs in figure 8 show the accuracy and loss of the model training with 10 epochs. The amount of time it takes for the model to optimize will ultimately depend on the length of the training data and amount of vocabulary. In our case, we trained the graphs in figure 8 with a vocabulary length of 1566 elements and a data size of about 100 x and y pairs.
Example outputs
Our LSTM model was successful at generating phrases. Here are two example outputs tried at
Epoch num: 12
Batch size: 196
Vocab size: 1566
Accuracy: 0.962
Loss: 0. 235
Figure 9.1 example output
'
Figure 9.2 example output
'
Conclusion
Our Bidirectional LSTM model was successful at generating the next words in a string. The model was able to produce sequences of syntactically and grammatically correct phrases nicely and consistently. In addition, the selection of data input helped provide an output that is curated to the context of biomedical professions. Unlike many other language models, ours is able to predict and correctly incorporate nomenclatures in the desired professional biomedical sphere.
Future Area of improvements
While our project focuses only on nomenclatures from the biomedical sphere, future research can improve upon this study by training the model on different professions to receive context-fitted outputs on a variety . If we can filter the input and add descriptive tags to the different fed into the training model, we can reduce the scope of the context of the text, thus then the generated output would match the desired sphere inputted by the user.
In addition, more LSTM layers can be added in order to detect more sophisticated sentence structure. Additional techniques such as reinforcement learning can be used to improve the accuracy model as well, and a context vector can be added to help the model better understand the context in which the sentence is written.
Acknowledgement
I wish to thank ASDRP, its stuff, and all of its sponsors or presenting me the opportunity to complete and present our research, and Mr. Suresh Subramaniam for instruction on deep learning, guidance throughout the completion of this project, and important pointers that helped solve a major debugging error during the process. Finally, my three other teammates Apoorva Kulshreshtha, Aditi Ghosh, Aditya Venkatraman for helping me with the brainstorm and research phase of the project.